Client Profile and Use Case:
The Client is involved in the domain of document processing, data capturing,document storage, customer verification and call center operations pan India.Client processes and stores large amount of CAF documents, both online and in physical forms. The online storage is done on in-house servers which require a large amount of manpower, infrastructure and software licenses among other things. Intent of this exercise is to look for an alternate cost-effective and reliable solution.
(Note: offline storage is out of scope for this exercise)
Amazon Glacier:
Once processed only a fraction of these thousands of documents are accessed. Hence archival is the best policy in this type of use-case. Amazon Glacier is the best solution for data archival it is both reliable and cost effective (0.01$ per GB/Month).
Upload Process on Amazon Glacier:
Process to upload documents on Amazon Glacier:-
- Firstly create a vault (Directory) in Amazon Glacier.
- Upload files in Glacier using API from the desktop App.
- Once uploaded, API returns a unique Achieve Id, which needs to be stored in database.

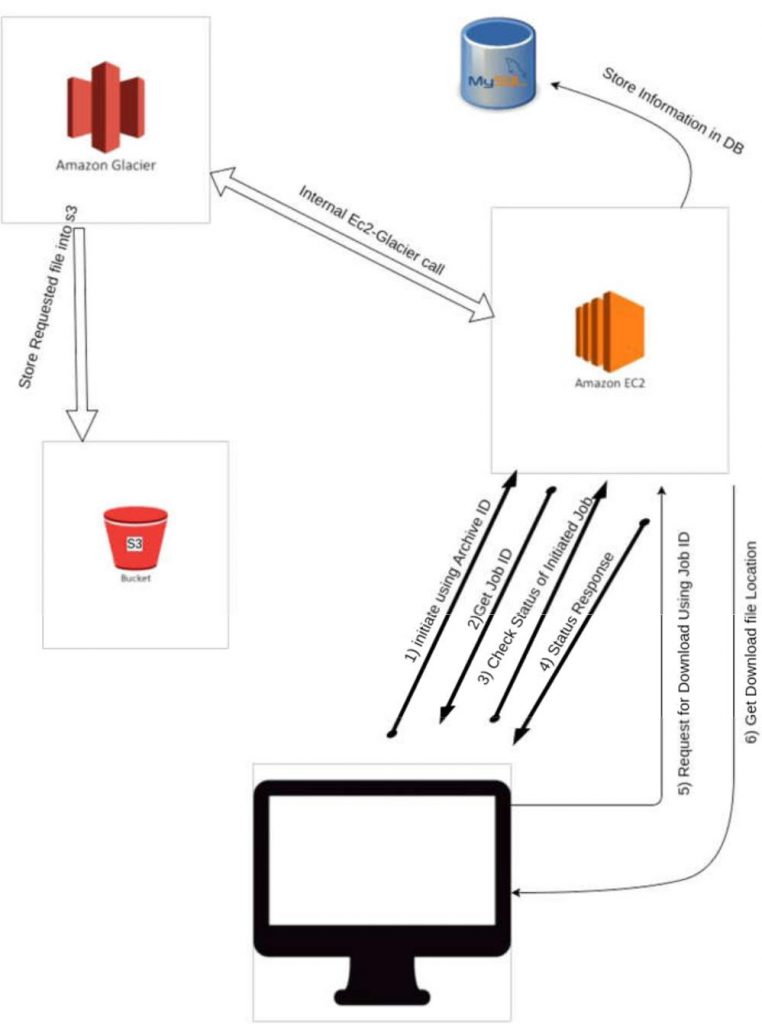
Download Process for Amazon Glacier:
Firstly we have to initiate a job (Retrieval process) using API for downloading a file using Archive Id, when we initiate a job we can pass the parameters like Tier(Standard, Expedited) and SNS(For Notification). After initiate process we will get a unique job-id that will be stored in database for further usage. The Standard tier takes retrieval time of 4 to 6 Hrs. and Expedited tier offers 1- 5 Min retrieval.
With the help of SNS, alert for retrieval process can be stetted; so that once the retrieval process is finished the user can get notification through Email/SMS/HTTP End point etc. When the retrieval process is complete, we will request for the download using API and Job-Id. In response API will return the download location of the file.